14 PDF Form and R Scraping
14.1 Overview
PDF forms have been used by several IEP survey teams as a way to streamline data collection and provide data entry QC while keeping the form development time and expense to a minimum See IEP E-device Survey responses.
R has been proposed as a tool for programmatically extracting the filled-in PDF form. The following is a presentation developed by Trinh Nguyen that examines the feasibility of R-scraping methods for PDF forms. Data scraping is the process of programmatically grabbing information from a webpage or document by analyzing the underlying code of the document.
14.2 Create a fillable PDF form
Fillable PDF forms can be developed using a number of programs, including Acrobat, Acrobat Reader (free) or Foxit editor (free version available). Other free software or web-based PDF form building and fillable conversion tools are available (e.g., Canva/DocFly or UPDF).
How to create fillable PDF forms with Adobe Adrobat
How to create fillable PDF forms with Foxit Editor
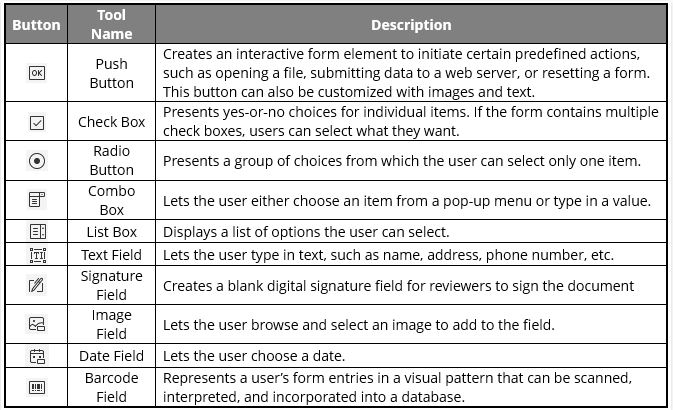
Figure 14.1: Potential field types available to insert as fillable forms in Foxit.
14.3 Analysis by Trinh Nguyen
The following is an evaluation of R-based methods for data extraction from PDF Forms prepared by Trinh Nguyen (IEP/CDFW) and presented to the DUWG subgroup in August 2023.
NOTE: The tabulizer library and code chunks are marked out in this bookdown document in order to simplify the Bookdown render. The full downloadable codes used for Trinh’s evaluation are included in Appendix 2: PDF R Scraping Demonstration
library(kableExtra)
library(dplyr)
#library(tabulizer)
library(tidyr)
library(stringr)
pdfRead <- here("images/PDF_Rscrape/pdfRead")Purpose: There are several PDF scraping packages in R. I will focus on two:
pdftoolstabulizer
14.4 Pros and Cons
- The main reason to consider this approach: cost. It is free.
- The main reasons to NOT consider this approach: nearly everything else:
- very code heavy
- no support
- scrapes only text-based data
-
tabulizercan be difficult to install if you run into Java restrictions
14.5 Outline
- Primer to ‘pdftools’
- Primer to ‘tabulizer’
- Case study: Bay Study datasheet
- Case study: DGS Pay Period Tables
- Conclusion
14.6 Primer to ‘pdftools’
- Primarily used to extract ONLY text-based data from a pdf
- Will read back all text as a singular string (ignoring structure)
pdftools::pdf_text("https://water.ca.gov/-/media/DWR-Website/Web-Pages/Programs/State-Water-Project/Operations-And-Maintenance/Files/Operations-Control-Office/Delta-Status-And-Operations/Delta-Operations-Daily-Summary.pdf")14.7 Primer to ‘tabulizer’
- Used to extract ONLY text-based data from a pdf
- Can extract formatted tabular data as tables
- However, tables must be formatted as tables
14.8 First Case Study: Bay Study
A PDF form was generated to match the current Bay Study datasheet

14.8.1 General Workflow
- If the data is tabular, use
extract_table()fromtabulizer - Non-tabular data will require more creative approaches
14.8.2 Extracting tabular data
Note: Output of these extract_table functions will not appear in the bookdown document because the tabulizer library is marked out. See Appendix 2 for full R code and example PDF files.
extract_tables(file.path(pdfRead,"Bay Study field sheet front_fill2_data.pdf"))extract_tables() has two algorithms to try and scrape tables. Can try both
extract_tables(file.path(pdfRead, "bayStudyExample.pdf"), method = "lattice")
extract_tables(file.path(pdfRead, "bayStudyExample.pdf"), method = "stream")Still does not work for the example Bay Study form!
One final approach is to specify the specific location of the data on the pdf.
locate_areas(file.path(pdfRead,"Bay Study field sheet front_fill2_data.pdf"))
Once data table is selected, extract_tables function can be applied successfully:
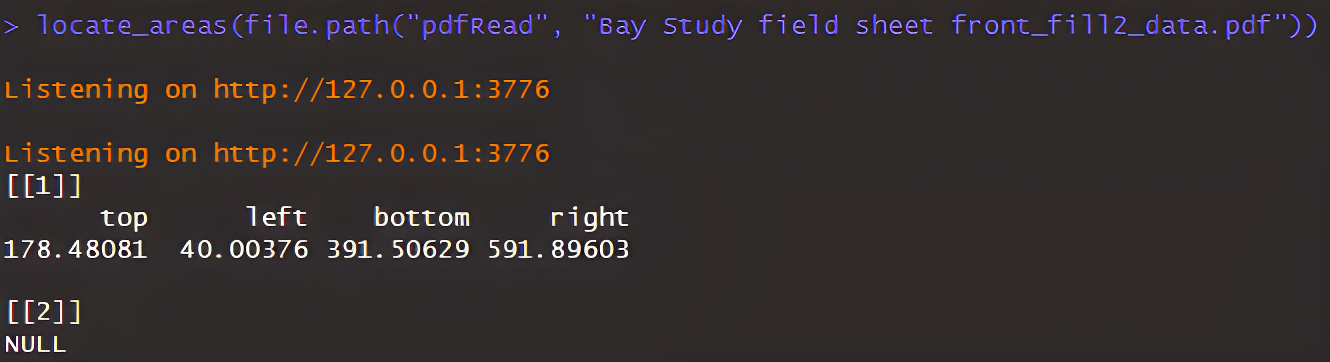
table <- extract_tables(file.path(pdfRead,"bayStudyExample.pdf"), pages = 1,
area = list(c(176.8358, 35.8913, 393.9738, 601.7659)),
guess = F, output = "data.frame")
table
table[[1]] %>%
.[-1, ] %>%
setNames(c("Species", "S", "Plus", "Specimen1", "Specimen2", "Specimen3",
"Specimen4", "Specimen5")) %>%
data.frame() %>%
pivot_longer(c("Specimen1", "Specimen2", "Specimen3",
"Specimen4", "Specimen5"),
# contains("Specimen"),
names_to = "Specimen", values_to = "Length") %>%
mutate(Sex = str_extract(Length, "[:upper:]"),
Length = str_extract(Length, "\\d+"),
across(c(S, Plus, Length),
as.numeric)) %>%
filter(!(is.na(S) & is.na(Plus) & is.na(Length) & is.na(Sex)))14.9 Second Case Study: DGS Pay Period Tables
tabulizer works well IF the datasheet is set up correctly.
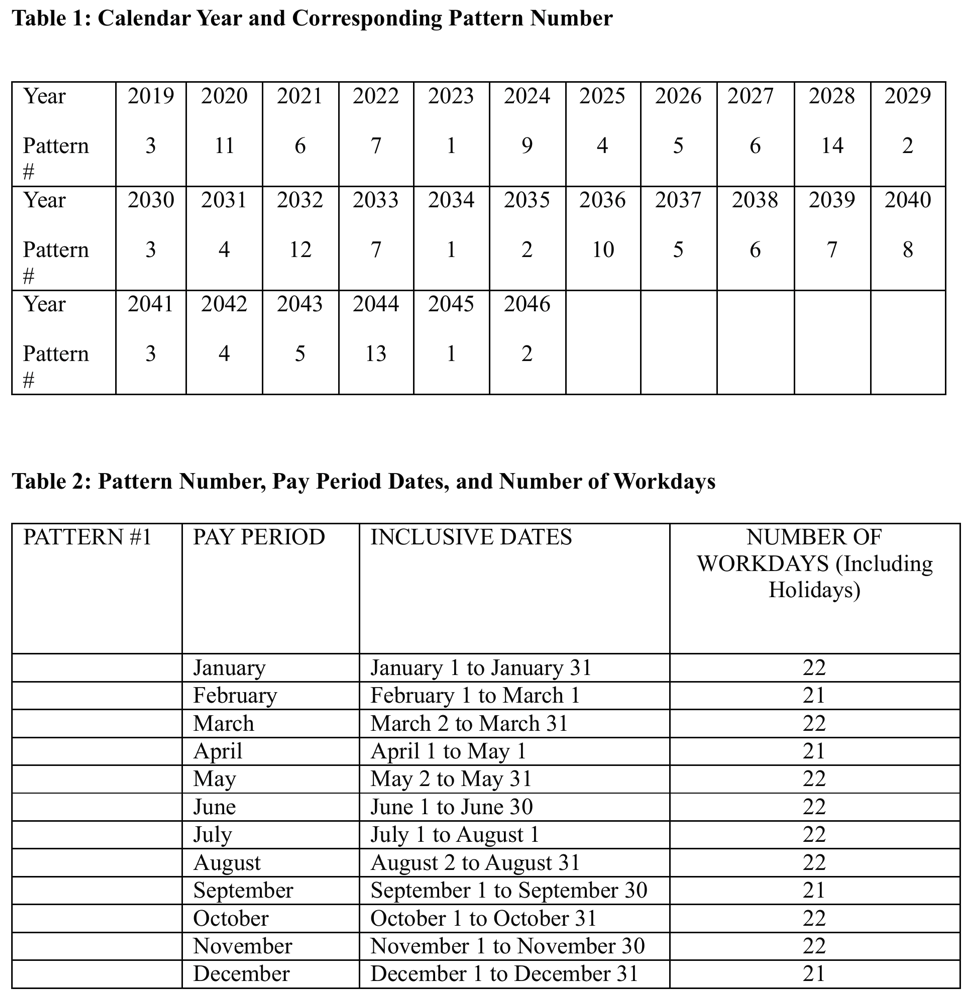
DGS Pay Period Tables
#|output-location: slide
tables <- extract_tables(file.path(pdfRead,"PayPeriodsDGS.pdf"), method = "stream")
tablesEasily workable, e.g., pay period information for the current month:
masterTableLocation <- which(sapply(tables, function(x) x[1, 1] == "Year"))
# Cleaning up the tables
# Table 6 is the master table showing which schedule table each year will follow:
masterTable <- data.frame(year = c(tables[[masterTableLocation]][1, 2:12],
tables[[masterTableLocation]][4, 2:12],
tables[[masterTableLocation]][7, 2:12]),
pattern = c(tables[[masterTableLocation]][2, 2:12],
tables[[masterTableLocation]][5, 2:12],
tables[[masterTableLocation]][8, 2:12])) %>%
mutate(across(everything(), as.numeric)) %>%
filter(!is.na(year))
priorityTable <- lapply(tables[-masterTableLocation], function(x) {
if (grepl("PATTERN", x[1, 1])) {
data.frame(x) %>%
mutate(pattern = gsub("[^0-9]", "", X1[1])) %>%
filter(X2 %in% c(month.name)) %>%
separate(X3, into = c("startDate", "endDate"), sep = " to ") %>%
transmute(pattern, month = X2, startDate, endDate, numberPaydays = X4)
} else {
data.frame(x) %>%
filter(X1 %in% c(month.name)) %>%
separate(X2, into = c("startDate", "endDate"), sep = " to ") %>%
transmute(month = X1, startDate, endDate, numberPaydays = X3)
}
}) %>%
bind_rows() %>%
fill(pattern, .direction = "down")
priorityTable %>%
filter(pattern == (masterTable %>%
filter(year == format(Sys.time(), "%Y")) %>%
pull(pattern)),
month == month.name[as.numeric(format(Sys.time(), "%m"))])14.10 Conclusion
- Possible
- Automate with
tabulizerandpdftools
However, there are major drawbacks:
- requires a non-trivial amount of coding knowledge in R
- can only scrape text-based data
- sensitive to structure of the datasheet
- no established workflow and dedicated features
- no support
- requires Java
14.11 Pros and Cons
| Features | ‘tabulizer’ | ‘pdftools’ |
|---|---|---|
| Ease of installation | Hard | Easy |
| Ease of use | Medium | Easy |
| Ease of application | Hard | Very Hard |
| Extract tables | Yes | No |
| Extract text | Yes | Yes |
| Automation | Yes | Yes |
| Code Knowledge | Medium High | Very High |
| Recommend | No | Very No |
14.12 Criteria Tables
For in-depth definitions of each criteria, see e-device comparison criteria.
14.12.1 Forms Options
| Category | Feature | Available | Description | Group Notes | External Reviews |
|---|---|---|---|---|---|
| Data entry validation/QC | Geo-referencing | No | |||
| Constrained choices from a list | Yes | Many types of fields available in PDF Adobe and Foxit | |||
| Rules guiding answer series (e.g., “Conditional Questions” and “Skips”) | No | ||||
| Constrained choices from an external table or set of rules | Yes | ||||
| Form Version Control | No | ||||
| Real-time Data Review | No | ||||
| Real-time Edit (“on the fly”) | No | ||||
| Ease of Form Development | Intuitive form design tool | N/A | |||
| Coding language required? | Yes | PDF extraction with R require very complex coding. | |||
| Different styles of question types | Yes | ||||
| Flexibility to configure in a logical order for field entry (e.g., nested desgin) | No | ||||
| Other IEP Survey needs | Permissions Management | No | |||
| Muti-users of an app | Yes | (anyone can share a PDF form) | |||
| Off-line capacity | Yes | ||||
| User Accessability | Multiple-language options | No | |||
| Font adjustment/ Speak-to-text | No |
14.12.2 Data Interface
| Category | Feature | Available | Description | Group Notes | External Reviews |
|---|---|---|---|---|---|
| Database interface | Cloud-storage | No | |||
| Direct integration with database | No | ||||
| Integrate data from local tables | No | ||||
| Edit after transfer | Editing data ‘on-the-fly’ (data already submitted) | No | |||
| Data format | Open (standard) format output | Yes | Once extracted, data will be available for R coding manipulations. | ||
| Data format logical / useable | Yes/No | PDF forms can be in non-tabular format which is very difficult to work with for data extraction routines. | |||
| Data transfer | Real-time data transfer | No | |||
| Cloud connectivity & back up | No | ||||
| Data change logs | Audit trails (data version control) | No |
14.12.3 Photo Integration and External Sensors
| Category | Feature | Available | Description | Group Notes | External Reviews |
|---|---|---|---|---|---|
| Photo Integration | Collect photo & assoc. with element | No | |||
| Ease of interface | No | ||||
| Multi-photo per element (and # limit) | No | ||||
| Drawing-on/ Annotating photo | No | ||||
| X-tern sensors | GPS from device | No | |||
| Integrate data from bar codes | No | ||||
| Integrate data from external sensors | No |
14.12.4 Hardware Platforms
| Feature | Available | Group Notes | External Reviews |
|---|---|---|---|
| Smart Phones and Tablets | |||
| - iOS (phone and tablet) | Yes | ||
| - Android(phone and tablet) | Yes | ||
| Desktop/laptop | |||
| - Windows 7,8,10, 11 | Yes | ||
| - MacOS (computer) | Yes | ||
| - Ubuntu Linux | Yes |
14.12.5 Security Factors
| Feature | Available | Description | Group Notes | External Reviews |
|---|---|---|---|---|
| Where’s the application/product origins from? | N/A | |||
| Is the application Cloud based, and if so, where? | No | |||
| Where is the data being stored for the application? | No | |||
| Is the data center FedRAMP certified? | No | |||
| Online Security measures | No |